

Łukasz Starzyk, Analityk Business Intelligence
Firmy uwielbiają zbierać wszelkiej maści dane. Kolekcjonują informacje o zamówieniach, transakcjach, klientach, pracownikach, czy nawet „lajkach na Facebooku”. Im więcej, tym lepiej. Wielu zarządzających firmami menedżerów głęboko wierzy, że analiza zebranych danych pozwoli im znaleźć przewagę na rynku, co w konsekwencji przełoży się na większy zysk firmy, zadowolenie akcjonariuszy… i większe premie dla menedżerów. O ile w najmniejszych firmach do zbierania danych czasem wystarczy po prostu pracownik obsługujący Excela, o tyle w tych większych organizacjach potrzebna jest hurtownia danych.
Każdy nowy projekt w organizacji, każdy nowy rynek, czy każda fuzja często niosą ze sobą utworzenie jednej lub więcej baz danych, które koniecznie trzeba zaciągnąć do hurtowni danych organizacji. Wielość i zmienność systemów źródłowych jest wielkim wyzwaniem, jakie stoi przed budowniczymi hurtowni.
Dla zobrazowania problemu, wyobraźmy sobie bank, w którym otwieramy nową działalność maklerską (i trzeba stworzyć bazę klientów domu maklerskiego, ich akcji, obligacji, transakcji, wpłat, wypłat…) i jednocześnie prowadzimy obligatoryjny projekt budowy bazy kredytów na potrzeby raportowania dla KNF. Dodajmy do tego fuzję z innym bankiem (a ostatnio sporo tego na rynku), w którym wszystkie dane są zbierane w zupełnie inny sposób, a które trzeba zintegrować i uwzględnić w głównej hurtowni. Brzmi jak lata pracy… i w sumie będzie to prawda.
Hurtownię można budować na wiele sposobów. Schematy gwiazdy czy płatka śniegu to klasyka modelowania hurtowni danych. Jednak wraz ze wzrostem liczby tabel importowanych do hurtowni, często stajemy przed problemem wydajności ładowania czy audytowalności przetworzonych danych. Nie mówiąc już o tym, by taka hurtownia była przyjazna dla użytkownika końcowego, co ze wzrostem liczby tabel może być problematyczne. Ideałem byłaby hurtownia, do której można bez problemu zaciągnąć nowe źródła, gdzie z łatwością prześledzimy dlaczego dane są takie a nie inne (tzw. procesy data lineage i impact analysis) i która będzie przyjazna w wykorzystaniu. Ideał, jak to ideał – pewnie nie istnieje. Ale Data Vault próbuje nas do niego przybliżyć.
Data Vault to stworzona przez Dana Linstedta koncepcja modelowania hurtowni danych, która w swoim zamyśle łączy zalety podejścia relacyjnego i wymiarowego. Nastawiona jest na śledzenie szczegółowych danych i ich historyzację, przy jednoczesnym dbaniu o audytowalność i szybkość przetwarzań. Brzmi to może nieco skomplikowanie, przejdźmy więc do konkretów i spróbujmy zamodelować przykładową hurtownię.
Pierwszym krokiem ku hurtowni Data Vault jest identyfikacja kluczy biznesowych w danych źródłowych. Mogą to być choćby klucze naturalne takie jak numery PESEL czy IBAN, czy klucze sztuczne pochodzące z systemów źródłowych. Zbiór kluczy danego typu ładujemy do tabeli typu hub – jest to podstawowy typ tabeli w modelu Data Vault. Huby są kośćmi, z których zbudujemy szkielet hurtowni.
W tabeli HUB_KLIENCI będziemy mieć klucze klientów ze wszystkich systemów źródłowych, wraz z informacją, z którego systemu rekord pochodzi. Dla przykładu, gdy importujemy dane klienta z systemów depozytowego, leasingowego i maklerskiego, zarys tabeli HUB_KLIENCI może wyglądać np. tak:
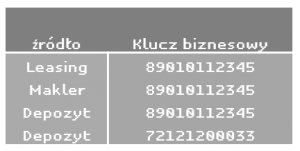
Na tym przykładzie widzimy, że jeden identyfikator pojawia się parokrotnie w różnych systemach źródłowych. To może być jedna osoba (np. gdy wszędzie kluczem jest PESEL), ale mogą to być również różne osoby, a może różne firmy – wszystko zależy od kontekstu. Przy budowie huba musimy o tym pamiętać i dobrze nazywać źródła rekordów, aby zapewnić unikalność rekordów na poziomie całego huba – pewnie każdy zetknął się z jakąś bazą, gdzie klucz w każdej tabeli brzmiał dumnie „ID” i przyjmował wartości 1,2,3,4….
Obiekty trzymane w różnych hubach oczywiście nie wiszą w próżni. Klienci kupują nasze Produkty, dokonują za nie Płatności, czasami klientowi przypisujemy dedykowanego doradcę spośród Pracowników. Wszelkie takie relacje zbieramy w tabelach typu link, które łączą ze sobą dwa huby, wskazując na istniejące powiązania biznesowe. Jeśli huby porównać do kości tworzących szkielet hurtowni, to linki będą stawami i ścięgnami naszego organizmu hurtowni.
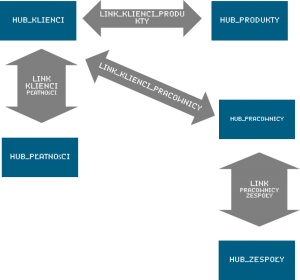
Komplet hubów i linków między nimi tworzy podstawę modelu hurtowni danych. Jednak zbiory kluczy i relacji nie dają wiele bez miar i wymiarów, opisujących dane obiekty czy relacje. Dlatego do każdego huba można dołączyć przypisane do nich tabele zwane satelitami. Satelity zawierają wszelkie dane opisowe dla rekordów z huba. Jeden satelita może być przypisana tylko do jednego huba, ale nic nie stoi na przeszkodzie, by jeden hub posiadał wielu satelitów, np:
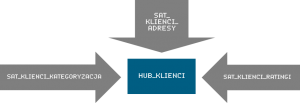
Podobnie jest z linkami. Do nich również można tworzyć satelity, szczególnie gdy chcemy opisać bardziej daną relację, niż którykolwiek obiekt z huba. Dla przykładu, wyobraźmy sobie Wniosek Kredytowy o kredyt hipoteczny, który przyjmuje jeden Pracownik, a decyzję kredytową podejmuje drugi. Wówczas może mieć sens utworzenie satelity do linku i trzymanie w niej informacji o funkcji, jaką pełnił każdy z pracowników podczas procesu kredytowego.
Powyższe przykłady to tylko podstawy. Istnieje kilka rodzajów bardziej specjalistycznych linków (np. Same-As wskazujący duplikaty z różnych systemów źródłowych wewnątrz jednego huba) czy satelitów (np. Multi-Active, które trzymają wiele rekordów dla jednego rekordu w hubie). Poza zasygnalizowaniem, nie będziemy jednak ich dalej opisywać, a jedynie odeślemy do bardziej specjalistycznych źródeł, wymienionych na końcu artykułu.
Z bardziej zaawansowanych obiektów warto wyróżnić tabelę pit (Point-In-Time). Jest to tabela stricte techniczna, która ma pomagać użytkownikom sprawnie korzystać z hurtowni danych. Powiązana jest z jednym hubem lub linkiem i wskazuje na rekordy każdego z satelitów, które obowiązują w danym momencie czasowym. Dzięki nim analitykowi łatwiej jest wyfiltrować rekordy w zapytaniu SQL jednym krótkim warunkiem w stylu „DATA_DANYCH = ‘2019-08-31’”, zamiast tworzyć skomplikowane zapytania na milionach rekordów trzymanych w satelitach.
Wiedząc już w ogólnych zarysach jak wygląda model hurtowni Data Vault, przejdźmy szczebel wyżej i rzućmy okiem na całą architekturę i zobaczmy, jak wygląda proces ładowania danych.
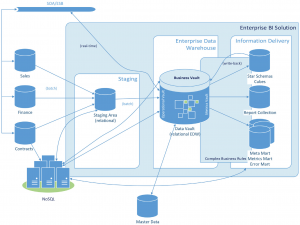
Źródło: Building a Scalable Data Warehouse with Data Vault 2.0
Najpierw dane surowe z systemów źródłowych są odkładane do pierwszej warstwy hurtowni, nazwanej tutaj staging. Tam nie chcemy nic zmieniać, co najwyżej dodać datę i godzinę ładowania.
Dalej dane wędrują do Data Vaulta, który dzielimy na dwie kolejne warstwy: Raw i Business. Najpierw trafiają do Raw Data Vault (w skrócie RDV), gdzie podlegają normalizacji i zasilają huby, linki i inne obiekty modelu Data Vault. Tutaj dane nie powinny jednak ulegać żadnym przekształceniom biznesowym – powinny dokładnie odzwierciedlać to, co jest odłożone w stagingu.
Zaletą posiadania Raw Data Vaulta jest jednak łatwość historyzacji danych oraz minimalizacja redundancji. Dzięki temu staging może być bardzo ulotną warstwą, w której dane są przechowywane tylko przez określony czas, np. przez miesiąc czy rok.
Kolejnym krokiem jest warstwa Business Data Vault (BDV), w której dane podlegają obróbce zgodnie z regułami biznesowymi. O ile RDV jest odzwierciedleniem systemów źródłowych, o tyle BDV zawiera już dane przyjazne w użyciu przez użytkowników posługujących się SQL-em, a nie znających konkretnych systemów źródłowych.
Na końcu są Information Marts, gdzie dane w Raw i Business Data Vault są wykorzystane do budowy baz pod konkretne raportowania. Dane w nich zawarte często są zagregowane, a same Information Marts mogą być zbudowane w innej strukturze niż Data Vault.
W tak skonstruowanej hurtowni mamy łatwość śledzenia zmian między kolejnymi warstwami, co znacznie ułatwia audyt. A zapewne każdy analityk pracujący przy hurtowni danych spotkał się z pytaniem w stylu „dlaczego w moim raporcie tutaj jest X a nie Y?”. Z drugiej strony podział na huby, satelity i linki pozwala na prostsze zaciąganie nowych źródeł do hurtowni, a w dzisiejszych czasach problem zmienności systemów źródłowych jest często większym problemem, niż sprzęt czy storage.
Dla zmieniającej się i rozwijającej organizacji wybór skalowalnej hurtowni danych może mieć wielkie znaczenie. Wówczas warto rozważyć model Data Vault.
Źródła wiedzy:
Daniel Linstedt, Michael Olschimke: Building a Scalable Data Warehouse with Data Vault 2.0, Elsevier Science, 2016
Daniel Linstedt: Data Vault Basics, http://danlinstedt.com/solutions-2/data-vault-basics/
Daniel Linstedt: Data Vault Series 1 – 5, http://tdan.com/data-vault-series-1-data-vault-overview/5054
Kent Graziano: Data Vault 2.0 Modeling Basics, https://www.vertabelo.com/blog/data-vault-series-data-vault-2-0-modeling-basics/